Linux内存地址空间[二]-VMA
原文作者兰新宇, 原文地址, 本文仅在原文的基础上进行了部分格式调整,对部分自己感觉文字较多的地方配上图片,以便于自己后续能够更好的理解。既然已经有人有写得好的文章了,那么自己也就懒得从头写了。要站在巨人的肩膀上(其实是因为我懒)。
一、segments
一个进程通常由加载一个elf文件启动,而elf文件是由若干segments组成的,同样的,进程地址空间也由许多不同属性的segments组成,但这与硬件意义上的segmentation机制(参考这篇文章)不同,后者在某些体系结构(比如x86)中起重要作用,充当内存中物理地址连续的独立空间。Linux进程中的segment是虚拟地址空间中用于保存数据的区域,只在虚拟地址上连续。

text段包含了当前运行进程的二进制代码,其起始地址在IA32体系中中通常为0x08048000,在IA64体系中通常为0x0000000000400000(都是虚拟地址哈)。data段存储已初始化的全局变量,bss段存储未初始化的全局变量。从上图可以看出,这3个segments是紧挨者的,因为它们的大小是确定的,不会动态变化。
与之相对应的就是heap段和stack段。heap段存储动态分配的内存中的数据,stack段用于保存局部变量和实现函数/过程调用的上下文,它们的大小都是会在进程运行过程中发生变化的,因此中间留有空隙,heap向上增长,stack向下增长,因为不知道heap和stack哪个会用的多一些,这样设置可以最大限度的利用中间的空隙空间。
还有一个段比较特殊,是mmap()系统调用映射出来的。mmap映射的大小也是不确定的。3 GB的虚拟地址空间已经很大了,但heap段, stack段,mmap段在动态增长的过程还是有重叠(碰撞)的可能。为了避免重叠发生,通常将mmap映射段的起始地址选在TASK_SIZE/3(也就是1 GB)的位置。如果是64位系统,则虚拟地址空间更加巨大,几乎不可能发生重叠。
如果stack段和mmap段都采用固定的起始地址,这样实现起来简单,而且所有Linux系统都能保持统一,但是真实的世界不是那么简单纯洁的,正邪双方的较量一直存在。对于攻击者来说,如果他知道你的这些segments的起始地址,那么他构建恶意代码(比如通过缓冲区溢出获得栈内存区域的访问权,进而恶意操纵栈的内容)就变得容易了。
一个可以采用的反制措施就是不为这些segments的起点选择固定位置,而是在每次新进程启动时(通过设置PF_RANDOMIZE标志)随机改变这些值的设置。

那这些segments的加载顺序是怎样的呢?以下图为例,首先通过execve()执行elf,则该可执行文件的text段,data段,stack段就建立了,在进程运行过程中,可能需要借助ld.so加载动态链接库,比如最常用的libc,则libc.so的text段,data段也建立了,而后可能通过mmap()的匿名映射来实现与其他进程的共享内存,还有可能通过brk()来扩大heap段的大小。

二、vm_area_struct
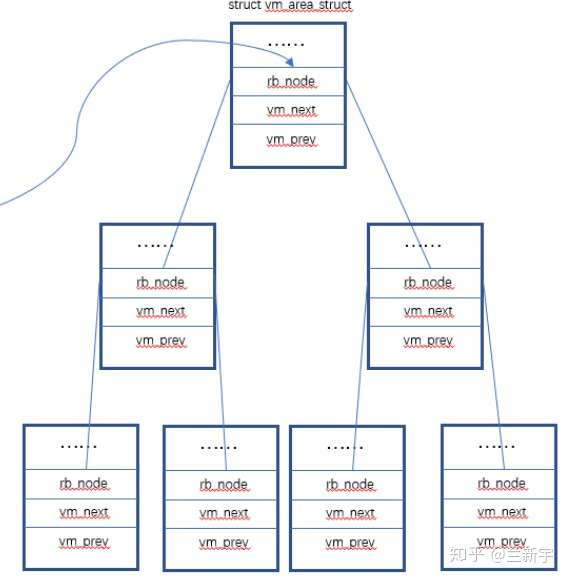
在Linux中,每个segment用一个vm_area_struct(以下简称vma)结构体表示。vma是通过一个双向链表(早期的内核实现是单向链表)串起来的,现存的vma按起始地址以递增次序被归入链表中,每个vma是这个链表里的一个节点。

在用户空间可通过”/proc/PID/maps”接口来查看一个进程的所有vma在虚拟地址空间的分布情况,其内部实现靠的就是对这个链表的遍历。

同时,vma又通过红黑树(red black tree)组织起来,每个vma又是这个红黑树里的一个节点。为什么要同时使用两种数据结构呢?使用链表管理固然简单方便,但是通过查找链表找到与特定地址关联的vma,其时间复杂度是O(N),而现实应用中,在进程地址空间中查找vma又是非常频繁的操作(比如发生page fault的时候)。
使用红黑树的话时间复杂度是:
尤其在vma数量很多的时候,可以显著减少查找所需的时间(数量翻倍,查找次数也仅多一次)。同时,红黑树是一种非平衡二叉树,可以简化重新平衡树的过程。
现在我们来看一下vm_area_struct结构体在Linux中是如何定义的(这里为了讲解的需要对结构体内元素的分布有所调整,事实上,结构体元素的分布是有讲究的,将相关的元素相邻放置并按cache line对齐,有利于它们在cache中处于同一条cache line上,提高效率):
struct vm_area_struct
{
unsigned long vm_start;
unsigned long vm_end;
struct vm_area_struct *vm_next, *vm_prev;
rb_node_t vm_rb;
unsigned long vm_flags;
struct file * vm_file;
unsigned long vm_pgoff;
struct mm_struct * vm_mm;
...
}
其中,vm_start和vm_end分别是这个vma所指向区域的起始地址和结束地址,虽然vma是虚拟地址空间,但最终毕竟是要映射到物理内存上去的,所以也要求是4 KB对齐的。
vm_next是指向链表的下一个vma,vm_rb是作为红黑树的一个节点。
vm_flags描述的是vma的属性,flag可以是VM_READ、VM_WRITE、VM_EXEC、VM_SHARED,分别指定vma的内容是否可以读、写、执行,或者由几个进程共享。前面介绍的页表PTE中也有类似的Read/Write权限限制位,那它和vma中的这些标志位是什么关系呢?
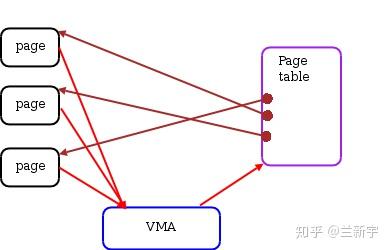
vma由许多的虚拟pages组成,每个虚拟page需要经过page table的转换才能找到对应的物理页面。PTE中的Read/Write位是由软件设置的,设置依据就是这个page所属的vma,因此一个vma设置的VM_READ/VM_WRITE属性会复制到这个vma所含pages的PTE中。
之后,硬件MMU就可以在地址翻译的过程中根据PTE的标志位来检测访问是否合法,这也是为什么PTE是一个软件实现的东西,但又必须按照处理器定义的格式去填充,这可以理解为软硬件之间的一种约定。那可以用软件去检测PTE么?当然可以,但肯定没有用专门的硬件单元来处理更快嘛。
可执行文件和动态链接库的text段和data段是基于elf文件的,mmap对文件的映射也是对应外部存储介质中这个被映射的文件的,这两种情况下,vm_file指向这个被映射的文件,进而可获得该文件的inode信息,而”vm_pgoff”是这个段在该文件内的偏移。
对于text段,一般偏移就是0。对于heap段,stack段以及mmap的匿名映射,没有与之相对应的文件实体,此时”vm_file”就为NULL,”vm_pgoff”的值没有意义。那一个进程是怎么找到它的这些vma的呢?请看下文分解。
参考: